Parallelism can take many forms in a cluster like Teton. What will help you better parallelize your workflow is knowing how it works.
Let us first take a look at the architecture of the systems you will be using.
HARDWARE:
The top level unit is called a node and there are 180 regular nodes (128 GB each), and 10 huge memory nodes (1024 GB each). Think of each node as being your desktop computer.
These nodes are further split into 32 cores. Your desktop computer could have between 4 and 12 cores.
And each of these cores have 1 thread each.
...
However, with SLURM you are allowed to break up those physical partitions into virtual/software things constructs to make it easier to use on a condominium cluster with hundreds of users.
The node still remains the highest unit in the hierarchy.
But now, a node is split up into tasks (also called process) and a task is split up into cpus.
And each of these cpus have 1 thread each.
...
Based on this, one can see how SLURM further splits the hardware resources so multiple users can access the same resource: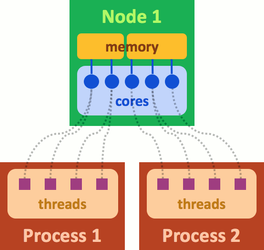
One thing that should stand out to you from the previous figure is that the two processes do NOT share memory between them. The yellow block is separated by a partition.
This leads us to one of the basic questions you need to ask yourself before you start a parallelization scheme.
Q. Can the different processes in my program run on separate blocks of memory (i.e. data) OR do they need to share the same memory space?
Based on your answer to that question, we can have multiple scenarios that play out in code.
- You want to run the same program on the same data but change the parameters for each run. This is called 'embarrassingly parallel'.
This basically means that you can run each process (i.e. program) independently with a different memory partition (i.e. data). However, since the data remain the same this basically means you can copy over the same data to the different memory partitions and run the program with the changed parameters. (SLURM allocation) - You could have a scenario in which you want to run a huuuuuge block of code which takes forever to run within a program. Let's say that this huge block of code contains loops (which it usually does).
One thing to note here is to see if each run of the loop is independent of the other. In other words, can you run the 10th iteration of the loop before the 5th?
If yes, then what you will have is 'shared memory parallelism'. (threading, clusters/apply in R, OpenMP, MPI) - You have a case in which the two programs are simultaneously working on two different data sets and in the third program, you receive the results after every 100th data point from the other two and change your analysis based on what you received. And this is happening recursively.
This means that you have access to two different memory chunks and two different process running simultaneously but your third process (with its own memory chunk) needs to communicate with the other two. This is called 'distributed memory parallelism'. (MPI)
Most of the cases I've seen have been of types 1 and 2. So the chances of your workflow being type 3 are pretty low but it is possible.
Now depending on what resources you want from Teton, you can make the following sbatch calls: https://arccwiki.uwyo.edu/index.php/Software:_Slurm#Batch_Jobs
So when you do a request for allocation, the default is: 1 node with 1 task per node and ~1GB of memory (RAM).
Notes to self: mention embarrassingly parallel, basic parallelism in r with apply family of functions, vectorization in r, running r with clusters (foreach, do parallel) and what options are required, threading with gnu parallel, asking for more memory (NOT more tasks/cpus),
...