Parallelism can take many forms in a cluster like Teton. What will help you better parallelize your workflow is knowing how it works.
HARDWARE:
The top level unit is called a node and there are 180 regular nodes (128 GB each), and 10 huge memory nodes (1024 GB each). Think of each node as being your desktop computer.
These nodes are further split into 32 cores. Your desktop computer could have between 4 and 12 cores.
And each of these cores have 1 thread each.
The terms specified above are all hardware partitions i.e. they physically exist on Teton.
SOFTWARE:
However, with SLURM you are allowed to break up those physical partitions into virtual/software things to make it easier to use on a condominium cluster with hundreds of users.
The node still remains the highest unit in the hierarchy.
But now, a node is split up into tasks (also called process) and a task is split up into cpus.
And each of these cpus have 1 thread each.
Here is an image linking the two together: (from http://www.maisondelasimulation.fr/smilei/parallelization.html)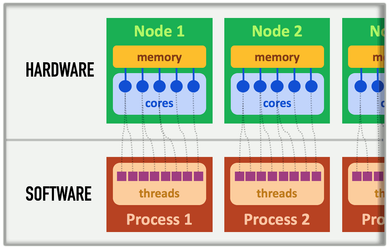
Based on this, one can see how SLURM further splits the hardware resources so multiple users can access the same resource: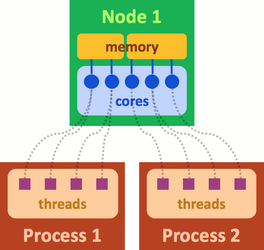
Now depending on what resources you want from Teton, you can make the following sbatch calls: https://arccwiki.uwyo.edu/index.php/Software:_Slurm#Batch_Jobs
So when you do a request for allocation, the default is: 1 node with 1 task per node and ~1GB of memory (RAM).
Notes to self: mention embarrassingly parallel, basic parallelism in r with apply family of functions, vectorization in r, running r with clusters (foreach, do parallel) and what options are required, threading with gnu parallel, asking for more memory (NOT more tasks/cpus),